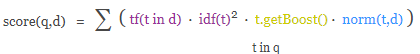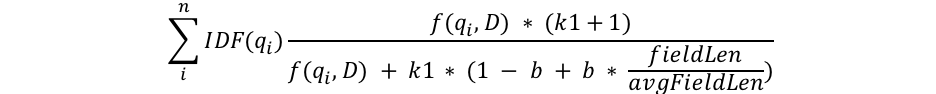1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
| {
"_index": "score",
"_type": "_doc",
"_id": "1",
"matched": true,
"explanation": {
"value": 0.2876821,
"description": "weight(name:yuanbo in 0) [PerFieldSimilarity], result of:",
"details": [{
"value": 0.2876821,
"description": "score(freq=1.0), product of:",
"details": [{
"value": 2.2,
"description": "boost",
"details": []
}, {
"value": 0.2876821,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [{
"value": 1,
"description": "n, number of documents containing term",
"details": []
}, {
"value": 1,
"description": "N, total number of documents with field",
"details": []
}]
}, {
"value": 0.45454544,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [{
"value": 1.0,
"description": "freq, occurrences of term within document",
"details": []
}, {
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
}, {
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
}, {
"value": 2.0,
"description": "dl, length of field",
"details": []
}, {
"value": 2.0,
"description": "avgdl, average length of field",
"details": []
}]
}]
}]
}
}
{
"_index": "score",
"_type": "_doc",
"_id": "2",
"matched": true,
"explanation": {
"value": 0.11955717,
"description": "weight(name:yuanbo in 0) [PerFieldSimilarity], result of:",
"details": [{
"value": 0.11955717,
"description": "score(freq=1.0), product of:",
"details": [{
"value": 2.2,
"description": "boost",
"details": []
}, {
"value": 0.13353139,
"description": "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details": [{
"value": 3,
"description": "n, number of documents containing term",
"details": []
}, {
"value": 3,
"description": "N, total number of documents with field",
"details": []
}]
}, {
"value": 0.40697673,
"description": "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details": [{
"value": 1.0,
"description": "freq, occurrences of term within document",
"details": []
}, {
"value": 1.2,
"description": "k1, term saturation parameter",
"details": []
}, {
"value": 0.75,
"description": "b, length normalization parameter",
"details": []
}, {
"value": 3.0,
"description": "dl, length of field",
"details": []
}, {
"value": 2.3333333,
"description": "avgdl, average length of field",
"details": []
}]
}]
}]
}
}
|